Learning Discrete Distributions by Dequantization
Learning Discrete Distributions by Dequantization
Abstract
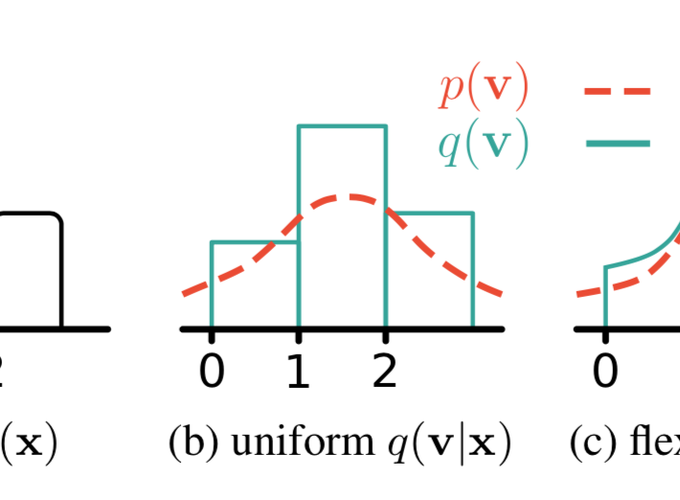
Media is generally stored digitally and is therefore discrete. Many successful deep distribution models in deep learning learn a density, i.e., the distribution of a continuous random variable. Naïve optimization on discrete data leads to arbitrarily high likelihoods, and instead, it has become standard practice to add noise to datapoints. In this paper, we present a general framework for dequantization that captures existing methods as a special case. We derive two new dequantization objectives: importance-weighted (iw) dequantization and Rényi dequantization. In addition, we introduce autoregressive dequantization (ARD) for more flexible dequantization distributions. Empirically we find that iw and Rényi dequantization considerably improve performance for uniform dequantization distributions. ARD achieves a negative log-likelihood of 3.06 bits per dimension on CIFAR10, which to the best of our knowledge is state-of-the-art among distribution models that do not require autoregressive inverses for sampling.