A quick motivation. Diffusion language models are attractive because they do not have to generate strictly from left to right. Instead of predicting one next token, they can revise many tokens in parallel.
There is one annoying catch. The model usually needs many denoising steps before the sequence becomes good. For continuous diffusion models, this has been attacked quite successfully by distillation. In our recent paper, Beyond Single Tokens: Distilling Discrete Diffusion Models via Discrete MMD, we ask: can we do something similar when the diffusion process is actually over discrete tokens?
The short answer is: yes, but you have to be a little careful.
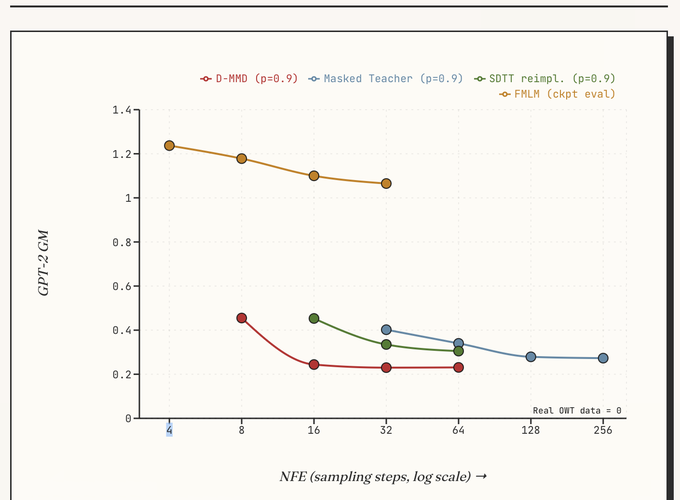
Before we go further, here some results: On a GPT-2 gradient moment metric, D-MMD moves close to the many-step teacher with far fewer denoising steps. Lower is better here: a small gradient moment means the samples sit closer to regions that a reference language model finds typical.
Headline. D-MMD outperforms a many-step teacher on GPT-2 gradient moment, but stays in the cheap few-step regime.
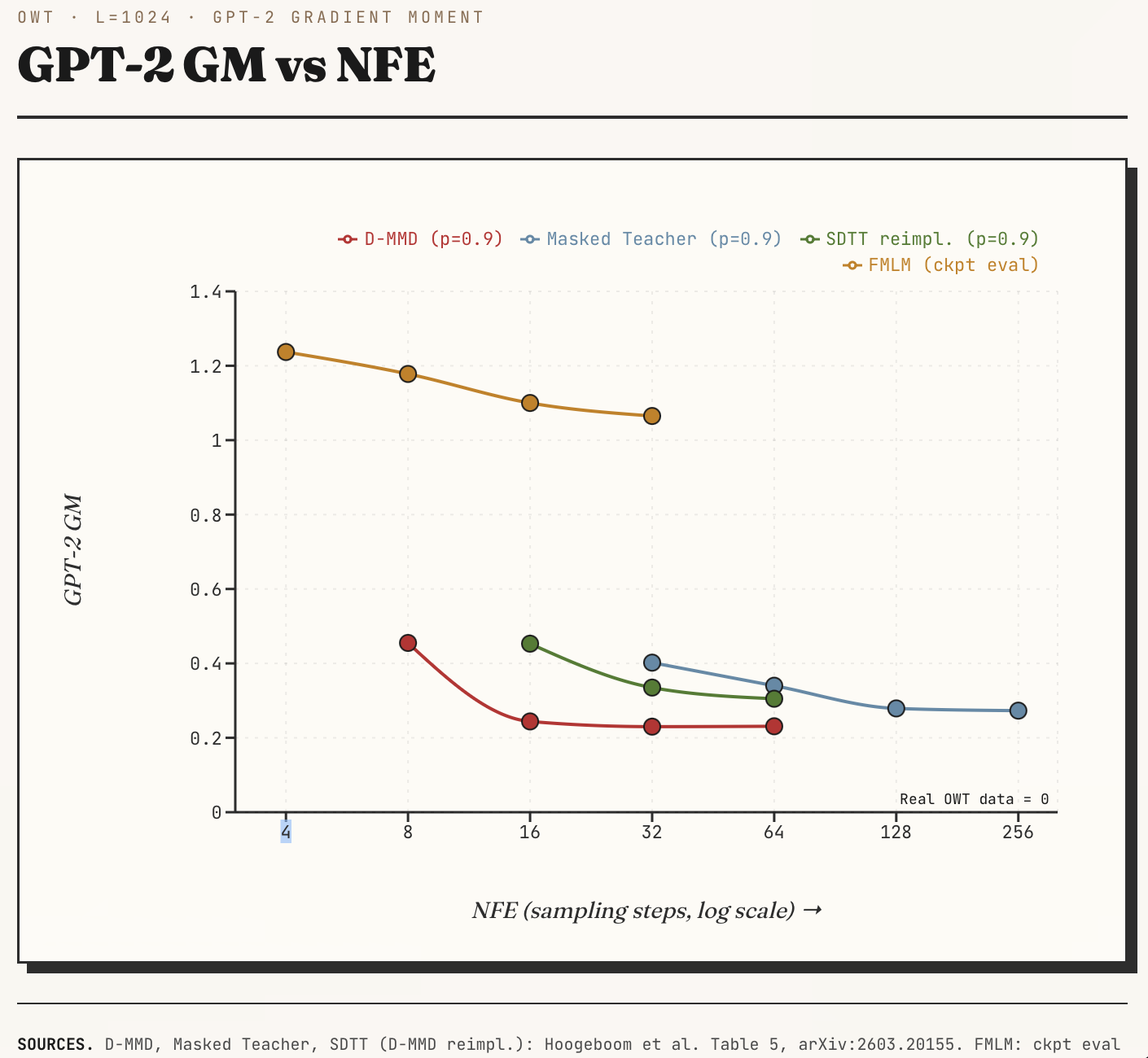
GPT-2 gradient moment versus sampling steps on OpenWebText. D-MMD reaches low gradient moment with far fewer denoising steps.
Why discrete is awkward
Main takeaway Continuous diffusion distillation has a deterministic flow map through the probability flow. Discrete diffusion has categories. Categories are wonderful for representing text, but they are less wonderful when you want to integrate a flow.
A typical discrete diffusion model corrupts a sequence, for example by masking tokens or replacing them with random tokens. The reverse model predicts the clean sequence again. In many implementations this prediction factorizes over positions:
$$p(x \mid z_t) = \prod_i p(x_i \mid z_t).$$
This is convenient, but slightly awkward. The model sees the whole noisy sequence, yet the clean prediction is still made token by token. If we take too large a denoising step, these independent guesses can become mutually inconsistent. A sentence is not just a bag of locally plausible tokens, unfortunately.
Moment matching
The method is inspired by Multistep Moment Matching Distillation. Very roughly, the continuous version says: at an intermediate noisy state, the student should have the same conditional expectation of clean data as the teacher. For images this is natural: pixels, latents, velocities, or noise predictions are continuous vectors.
For tokens, the expectation is a probability vector over the vocabulary. This is not a bad object at all. It just lives on a simplex, and the losses we use are usually cross-entropies rather than squared errors.
So the main move in D-MMD is to write moment matching in a form that does not care whether the loss is a squared error or a cross-entropy. We introduce an auxiliary model that learns what the student distribution looks like after taking a step. The student is then trained toward the teacher prediction and away from the auxiliary prediction. That is the small trick: we are not pretending that tokens are continuous, we are matching the right discrete object.
The generator loss has a pleasantly direct form:
$$\begin{aligned}\mathcal{L}_{\mathrm{gen}}(\eta) &= w(t)\left[\mathrm{CE}\left(\hat{x}_\eta(z_t)\mid\hat{x}_\theta(z_s)\right) - \mathrm{CE}\left(\hat{x}_\eta(z_t)\mid\hat{x}_\phi(z_s)\right)\right] \\ &= -w(t)\sum_c \hat{x}_{\eta,c}(z_t)\left(\log \hat{x}_{\theta,c}(z_s)-\log \hat{x}_{\phi,c}(z_s)\right).\end{aligned}$$
Here $\theta$ is the teacher, $\phi$ is the auxiliary model, $\eta$ is the student, and $w(t)$ is the time-dependent weighting term. The update simply gives more mass to tokens whose teacher log-probability is higher than the auxiliary log-probability.
What happens?
The pleasing result is that the distilled generators can use far fewer denoising steps, while keeping good sample quality and diversity. On text, a 16-step D-MMD generator can match a 256-step teacher in a block diffusion setup. On image-like discrete data, the distilled generator can even outperform the teacher at a fraction of the steps.
Headline. On the PPL–entropy plane, D-MMD moves onto the Pareto front: low generative perplexity without giving up sample diversity.

A perplexity–entropy Pareto view on OpenWebText. D-MMD moves onto the frontier among few-step and distilled baselines.
This last point is a little counterintuitive. My current interpretation is that likelihood-trained teachers are quite mode-covering, while distillation can behave a bit more like sample-quality optimization. For text we also avoid leaning too much on generative perplexity: repeated, boring text can score well there. So we use distributional metrics such as GPT-2 moments instead.
Relation to distilled continuous models
FMLM and DFM take the continuous/flow-map route: build a denoising trajectory that can be compressed into very few steps. They ask the same practical question as D-MMD: can we keep the parallelism of diffusion, but stop paying for hundreds of evaluations?
The Pareto figure is useful because this is not a one-dimensional race. A low NFE number is not enough, and neither is low generative perplexity by itself. We also want the samples to retain realistic diversity. D-MMD sits in this comparison as a discrete-token distillation method: instead of learning a continuous flow map and decoding back to tokens, it keeps the denoising object as token probabilities and matches moments there.
So I see D-MMD as complementary to the continuous distilled models. FMLM and DFM show how far one can go by making language generation look more like continuous diffusion. D-MMD asks how much of that distillation machinery can be translated back into the native discrete setting.
In summary. D-MMD distills discrete diffusion models without pretending that categorical tokens are Gaussian variables. It keeps token probabilities as the object to match, uses an auxiliary model to make moment matching practical, and gives few-step generators that are much cheaper to sample from.
Closest related work
A small shout-out to two close neighbors. Di[M]O is the clearest precursor on masked discrete diffusion distillation: a one-step image-token generator with an auxiliary model, and in that one-step masked setting the algorithm is essentially the same implementation as D-MMD. IDLM is concurrent and complementary for diffusion language models. If D-MMD is the moment-matching (MMD) route, ILDM is the DMD route.
Code
For people who want to play with the ideas in a smaller setting, I also keep an unofficial implementation for smaller models here: github.com/ehoogeboom/discrete-diffusion-lm.